Hvad er stabil diffusion, og hvordan man maksimerer dens kraft
Fremskridtet inden for kunstig intelligens overtager nu nogle programmer, der vil hjælpe med at generere billeder. Du kan muligvis se værktøjet Stabil diffusion. Men hvad er stabil diffusion? Dette er et billedgenererende værktøj. Dens primære formål er at generere billeder ved hjælp af prompter, og folk finder det tiltalende og sjovt at generere forskellige karakterer og elementer sammen. Lær mere om, hvad der er stabil diffusion, og find ud af, hvordan det virker.
Vejledningsliste
Del 1: Hvad er stabil diffusion Del 2: Hvad er VAE stabil diffusion Del 3: Hvad er Dreambooth på stabil diffusion og hvordan man installerer Del 4: Hvad er CFG-skala i stabil diffusion Del 5: Hvad er Denoising Styrke Stabil diffusion Del 6: Hvad er Clip Skip Stabil Diffusion og hvordan man bruger Del 7: Hvad er stabil diffusionsgenererende hastighed og hvordan man accelererer Del 8: Ofte stillede spørgsmål om stabil diffusionDel 1: Hvad er stabil diffusion
Det er en dyb læring, tekst-til-billede-model, der skaber billeder ved at indtaste prompter for at beskrive hovedemnet. For eksempel kan du sætte 'kat', og værktøjet vil generere et billede af en kat. Det kan dog yderligere understrege eller tilføje flere detaljer, når du indtaster komplekse prompter. Det generative neurale netværk bliver mere end et AI-værktøj, da det også er betinget med andre opgaver såsom overmaling, indmaling og billed-til-billede-oversættelse via tekstprompter.
Stable Diffusion blev udviklet og finansieret af Stability AI, men CompVis-gruppen ved Ludwig Maximilian Universitetet i München har den tekniske licens til den latente diffusionsmodel. Ydermere blev udviklingen ledet af forskerne Patrick Esser og Robin Rombach, der indhentede flere træningsdata fra non-profit organisationer i Tyskland som tilhængere af projekterne. Senere i oktober 2022 rejste virksomheden US$101 millioner efter at have introduceret det i august 2022.
Del 2. Hvad er VAE stabil diffusion
Du er muligvis stødt på dette, når du brugte AI-fotogeneratoren, og VAE er nyttigt for værktøjet. VAE står for Variable Auto Encoder, der bruges til at finjustere dekoderen for at male bedre detaljer. Det er en tilføjelse til AI-værktøjet, da det kan hjælpe med at få skarpere billeder og levende farver og forbedre genereringen af hænder og ansigter.
Selvfølgelig er VAE til mere end bare stabil diffusion, fordi alle modeller har indbyggede VAE'er til at regne ud detaljerne. Sammenligningen vil være resultatet mellem hver model, og hvordan de vil blive, når du komprimerer billederne. Desuden er der separate VAE-filer, som du kan downloade på din enhed. For at prøve en dekoder kan du bruge følgende:
- Orangemix/alt VAE til anime.
- Kl-f8-anime2 til anime.
- Vae-ft-mse-840000-ema-beskåret til realisme eller malerier.

Del 3. Hvad er Dreambooth på stabil diffusion og hvordan man installerer
DreamBooth er en deep learning generation model, der finjusterer genererede billeder, især det specifikke emne. I første omgang er den baseret på Imagens tekst-til-billede model, men desværre har Imagen ikke de fortrænede vægte som Stable Diffusion eller andre AI-værktøjer. DreamBooth blev videreudviklet af Google Researchers og nogle kolleger fra Boston University i 2022.
Modellens arbejde er at modificere og finjustere genererede billeder, men den er også i stand til at gengive velkendte motiver i enhver indstilling og situation. Da de fleste præ-trænede diffusionsmodeller stadig skal forbedres i denne kategori, vil DreamBooth booste træningen for diffusionsmodeller. Med kun fem billeder kan billedændringer udføres med platforme som Stable Diffusion. Her er en kort instruktion i, hvordan du bruger DreamBooth på stabil diffusion:
Trin 1.For det første skal du have træningsbilleder af ét emne til brug på DreamBooth. Sørg for, at motivet har taget billeder. Fortsæt med at ændre størrelsen på billederne til 512x512 pixels.
Trin 2.Åbn DreamBooth og indtast Forekomstprompt og Klasseprompt. Behandle ændringerne ved at klikke på Spil knappen fra venstre del af grænsefladen.
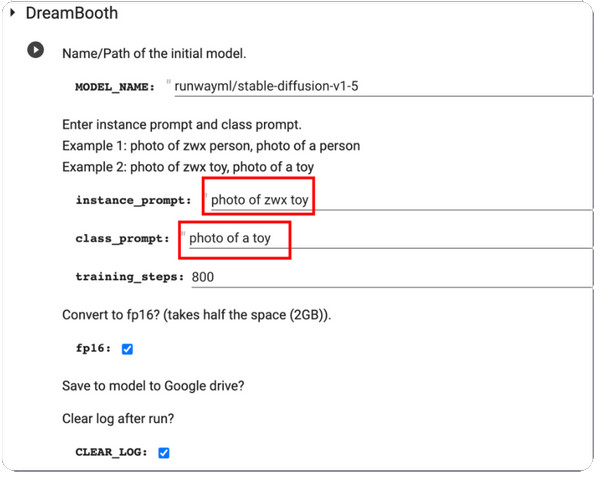
Trin 3.Når du er færdig, test den, og du vil modtage et par prøver genereret af modellen. Du kan downloade modelcheckpoint-filen fra dit Google Drev og installere den i GUI'en.

Del 4. Hvad er CFG-skala i stabil diffusion
Du kan finde denne værdi indstillet i fotogeneratormodellen. Og da det er essentielt, skal du lære, hvad der er værd at optimere billeder. Classifier Free Guidance Scale giver brugerne mulighed for at justere tætheden af resultatet fra inputbilledet eller de anvendte prompter. For eksempel, når du justerer CFG-skalaen til en mere fremragende værdi, vil output være mere lig inputbilledet, men forventes at blive forvrænget. På den anden side vil en lavere CGF-skala få output langt væk fra den primære prompt, mens den genererer bedre kvalitet.
Men hvornår skal du bruge CFG-skalaen på stabil diffusion? Svaret er enkelt: AI-fotogeneratoren kan ikke skabe noget, der ikke er inden for dens viden, så CFG-skalaen hjælper dig med at forbinde flere emner ved at skrue op for dets værdi. Den eneste ulempe er udgiften til billedkvalitet, som er proportional med meddelelserne. Hvis du er interesseret i dette værktøj, skal du øve dig i at kalibrere vægten for at finde det søde sted.

Del 5. Hvad er Denoising Styrke Stabil diffusion
Denne metode starter en proces, der tilføjer støj til inputbillederne. Det er bare en Stabil diffusionsopskaler. Det er en fremragende værdi for stabil diffusion, da det kan komme gennem billede-til-billede (img2img) eller InPaint. Støjmængden styres af Denoise Strength, fra et minimum på 0 til et maksimum på 1. Hvis værdien sættes til 0, reduceres støjen til ingen, hvilket giver et billede, der ligner inputbilledet. Ellers vil værdien 1 erstatte input med støj.
Du kan bruge Denoise Strength som en praktisk metode til at bestemme outputtets nærhed med inputbilledernes indflydelse. Et godt eksempel er en lavere Denoising Strength, der får genererede billeder til at se tættere på inputtet, en ideel indstilling for mindre ændringer. På den anden side vil Higher Denoising Strength sandsynligvis øge variationen og samtidig reducere ligheden mellem input- og outputbillederne. Derfor er højere værdier nyttige til væsentlige ændringer.

Del 6. Hvad er Clip Skip Stabil Diffusion og hvordan man bruger
CLIP er kendt som et indlejringslag, der bruges til at analysere tekster. Dets struktur er sammensat af lag, som pr. individ er mere specifikke end det foregående. For eksempel kan lag 1 være "Person", og lag 2 vil være "kvinde" eller "mand". Derefter vil det næste lag være "forælder, far, mand, dreng osv."
Dens formål er at få den præcise tekstmodel, som stopper den lange liste af lag, og til sidst blander flere data og giver dig mere, end du har brug for. Det bedste eksempel på dette er 1,5-modellen med 12 rækker dyb. Hvert lag har tekstindlejring og kan blandes med andre detaljer, såsom størrelse, farve osv. CLIP springer tekstrummets dimension over og kommer til det nøjagtige output. Sådan bruger du det:
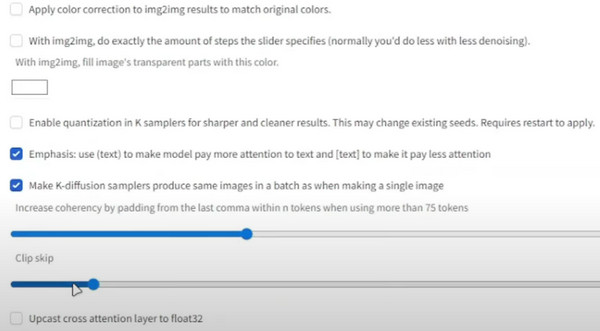
Trin 1.Fra kontrolpunktet for stabil diffusion skal du gå til indstillinger og vælge "Stabil diffusion".
Trin 2.Rul ned og gå til "Klip springes over". Indstil den til den ønskede værdi, og rul derefter op for at klikke på knappen "Anvend indstillinger".
Del 7. Hvad er stabil diffusionsgenererende hastighed og hvordan man accelererer
Når du ser på hastigheden af en AI-generator, vil du forvente, at det vil tage noget tid at vise resultater. Stabil diffusion har dog en genereringshastighed på 10 sekunder. Dette er kun til generel brug af onlineværktøjet, men tiden kan stadig skære op til fire sekunder, når du abonnerer på den primære eller standardplan. Dette er en måde at accelerere modellens hastighed på, men resultatets nøjagtighed går væk fra inputtet Stabil diffusion prompter. Desuden er værktøjet gratis med kun nogle få funktionsbegrænsninger fra de prissatte planer. Så hvordan accelererer du genereringshastigheden, mens du ikke betaler?
Det eneste krav til acceleration er et Nvidia-kort, som kan være i 4000-, 3000-, 2000- og endda 1000-serien. Du kan bruge Lovelace, Ampere, Pascal Turing osv. Som et alternativ skal du bruge en lavere præcision som float16 og køre færre inferenstrin.
Bonustips: Skift størrelse på stabile diffusionsresultater
Efter at have lært om AI-modellen, er der en ting mere, du skal vide: filstørrelse er en enorm faktor for billeder, og de kan æde din lagerplads op på grund af større filstørrelser. Men med AnyRec gratis billedkompressor online, vil det være praktisk at komprimere billederne. Onlineværktøjet har den nyeste AI-teknologi til at hjælpe med at optimere uploads og samtidig reducere filstørrelsen. Da det genererer mindre filer, kan brugeren importere flere billeder fra den lokale mappe, og kompressoren indlæser dem med det samme.
- Komprimer stabil diffusionsgenererede billeder med kvalitet.
- Der er ikke påført noget vandmærke på de komprimerede billeder.
- Understøtter formater som JPEG, GIF, TIFF, BMP, PNG og mere.
- Reparer automatisk de forvrængede, slørede og udfyld nye pixels på billedet.
Del 8. Ofte stillede spørgsmål om stabil diffusion
-
1. Kan jeg bruge Stable Diffusion offline?
Ja. værktøjet kan bruges uden internetforbindelse. Dette skyldes, at den kan gemme de syntetiske data lokalt, hvilket giver AI-modellerne træning i at blive brugt uden et internetnetværk.
-
2. Hvad er ulemperne ved AI-fotogeneratoren?
Udover dets fordele kan værktøjet være beregningsintensivt, mens det bruger tid, når det skal håndtere billeder og videoer med mere omfattende data. En anden er, at kvaliteten afhænger af de anvendte inputdata og netværksparametre. Det betyder, at der ikke er nogen garanti for, at du får et billede af høj kvalitet.
-
3. Har jeg brug for avanceret udstyr, når jeg bruger stabil diffusion?
Nej. Fotogeneratoren kan bruges uden den seneste computerversion. Selvom du har den nyere version, vil det være nok at bruge AI-generatoren.
-
4. Hvor kan man få tekstbeskeder?
Stable Diffusion har en indbygget tekstpromptingeniør, der hjælper dig med at søge efter prompter. Indtast blot en tekst og klik på knappen Søg. Resultaterne vises på få sekunder med billeder som eksempler.
-
5. Hvilken GPU skal jeg bruge for at køre onlineværktøjet?
Da den understøtter de fleste GPU'er, kan du køre AI-billedgeneratoren med Nvidia og AMD på 6 GB
Konklusion
Dette indlæg forklarer hvad er stabil diffusion og hvordan det virker med Clip Skip, VAE, DreamBooth, CFG Scale og Denoising Strength. På den anden side kan du bruge AnyRec Free Image Compressor Online til at reducere filstørrelserne på de genererede billeder. Det er helt gratis og ubegrænset at bruge!
Relaterede artikler:
Om vores forfatter



